A feature that Yahoo has that I wish Google had:
July 30th, 2008
No comments
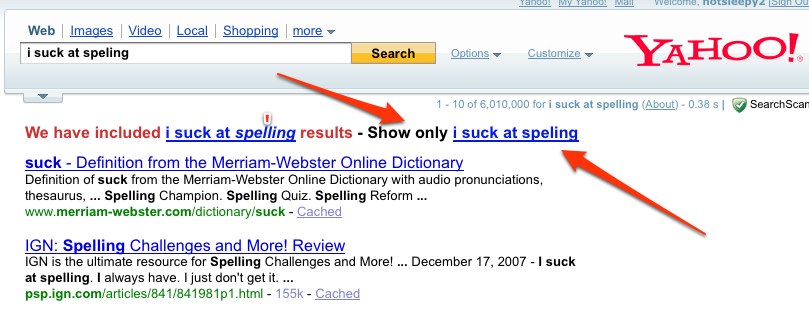
Google sometimes I know better than you and want to see results without you thinking for me.
Categories: Google
Google sometimes I know better than you and want to see results without you thinking for me.
A couple of months ago Google officially announced it would be “exploring some HTML forms to try to discover new web pages“. I imagine more than a few SEO’s were baffled by this decision as was I but were probably not too concerned about the decision as Google promised us all “this change doesn’t reduce PageRank for your other pages” and would only increase your exposure in the engines.
During the month of April I began to notice a lot of our internal search pages were not only indexed but outranking the relevant pages for a user’s query. For instance, if you Googled “SubConscious Subs” the first page to appear in the SERP’s would be something like:
http://raleigh.ohsohandy.com/ads/search?q=tables
rather than the page for the establishment:
http://raleigh.ohsohandy.com/review/27571-sub-concious-subs
This wasn’t just a random occurrence. It was happening a lot and in addition to the landing pages being far less relevant for the user, they weren’t optimized for the best placement in the search engines so they were appearing in position #20 instead of say position #6. These local search pages even had pagerank usually between 2 and 3.
Eventually I began to realize how often I was running into this in Google, noticed my recent, slow, decline in traffic and it occurred to me this may be a real problem. I’ve never linked to any local search pages on OhSoHandy.com and I couldn’t see that anyone else had either. I queried to find out how many search pages Google had indexed:
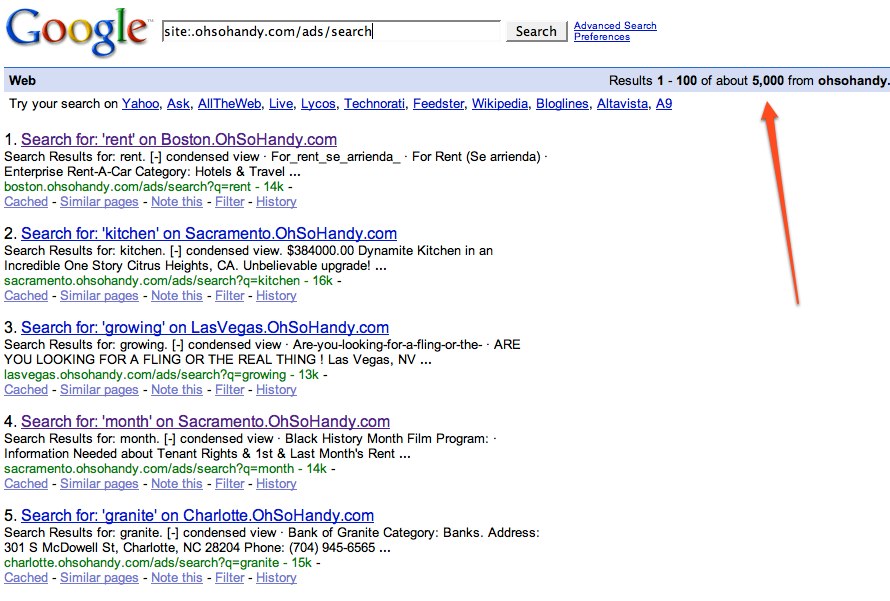
Whoa. 5,000+ pages of junk in the index with pagerank. I slept on it for a night, got up the next morning and plugged in
Disallow: /ads/search?q=*
in robots.txt (and threw in a meta robots noindex on those pages for safe measure). Within a week we saw a big improvement in rankings due to properly optimized pages trumping crap and traffic is up 25% since the change and back to trending upwards weekly instead of stagnant, slow decline.

The robots.txt disallow works but it is slow to remove the URL’s from Google’s index. I added the meta noindex tag to the search pages a week later and saw much faster results.
 For some time now I’ve been telling clients and friends that publishing duplicate content will not cause you to receive a penalty but that Google will only choose one version of a unique piece of content that it believes to be the authority and refuse to allow other copies to be indexed. So if you publish a copy of one of my blog posts, Google will likely allow my original copy to rank but yours won’t be found.
For some time now I’ve been telling clients and friends that publishing duplicate content will not cause you to receive a penalty but that Google will only choose one version of a unique piece of content that it believes to be the authority and refuse to allow other copies to be indexed. So if you publish a copy of one of my blog posts, Google will likely allow my original copy to rank but yours won’t be found.
I think I’ve discovered that enough duplicate content can actually do harm to a domain.
I had an old site we’ll call oldsite1.com. I was publishing fresh, unique, well written content there several times a day. oldsite1.com would always enjoy nice rankings for the content published there and new content was indexed quickly. I had always intended to eventually 301 redirect all of oldsite1.com’s pages to newsite1.com which would be hosting identical content. Past experience tells me that the 301 will cause all of oldsite1.com’s backlinks and authority to transfer over to newsite1.com and within days I’d see the new site perform nearly as well as the old site’s.
Now here is the mistake I made: some time ago I setup newsite1.com to mirror oldsite1.com (for some offline promotional reasons). I had zero backlinks to newsite1.com but it was crawled and indexed anyway. Obviously it was 100% duplicate content and nothing but duplicate content. But I didn’t worry too much about it. The day came to 301 redirect and within days the traffic plummeted. Its been several weeks and no recovery has happened.
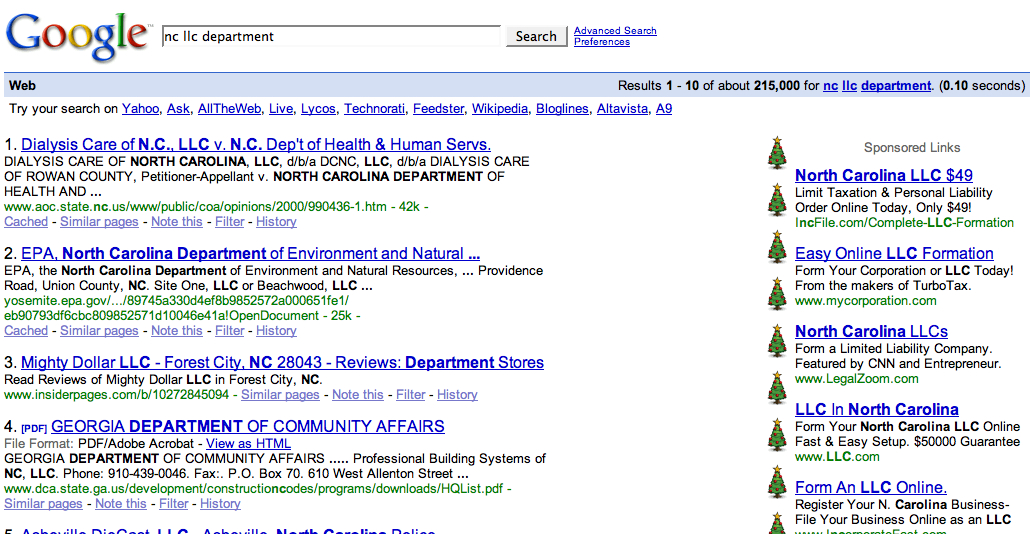
Weirdness. I’ve never seen clipart next to Adwords in the SERPs but look at these funky Christmas tree icons next to the ads when searching for NC LLC Department:
On my way home Friday I found myself behind one of the Immersive Media cars that I assume was scanning streets in Raleigh for Google Street View. These are crap photos but my camera on my phone is crap. The Beetle had www.immersivemedia.com across the back window and Oregon plates.
Horrible screen capture from video

Read more…

